Um dos assuntos que está em alta na mídia nos últimos tempos é a Inteligência Artificial (IA), que cada dia é capaz de cada vez mais coisas, desde atividades simples como automatizar atendimentos até atividades mais complexas, como escrever um trabalho inteiro para a escola ou faculdade.
Uma das atividades que comecei a me apaixonar recentemente foi a criação de imagens utilizando IA, especificamente com uma ferramenta chamada Stable Diffusion (ou SD), somado com uma interface web chamada Automatic 1111 (ou A1111), que torna tudo mais simples, principalmente para aquelas pessoas que não são da área de tecnologia.
O objetivo deste tutorial será ensinar os recursos básicos do A1111, e consequentemente do Stable Diffusion.

Observações Importantes:
- Você vai precisar de uma placa de vídeo dedicada. Apesar de rodar em placas de vídeo da AMD, as placas da Nvidia possuem resultados consideravelmente mais rápidos. O requisito mínimo é possuir uma Geforce 970 com 4GB de VRAM, mas para uma velocidade satisfatória, recomendo uma placa de vídeo da série RTX 3070 ou superior, com pelo menos 8GB de VRAM (no momento em que escrevo este tutorial, a série RTX 4000 é a mais atual).
- Não vou abordar neste tutorial assuntos avançados, como Low Rank Adaptations (LORAs), Control Net, Reverse Tagging, entre outros.
- A versão 1.4.1 do Automatic 1111 e 1.5.0 do Stable Diffusion foram as utilizadas como base para a confecção deste tutorial. Se você está lendo este tutorial em data posterior, pode ser que algumas dicas não sejam válidas, portanto fique atento.
Instalando pré-requisitos
Antes de começar a fazer as artes, precisamos fazer a instalação de alguns recursos em nosso computador.
Para isso, abra este link, que deverá levar você para a página do A1111, na seção de “Automatic Installation on Windows”, conforme mostrado na imagem abaixo:
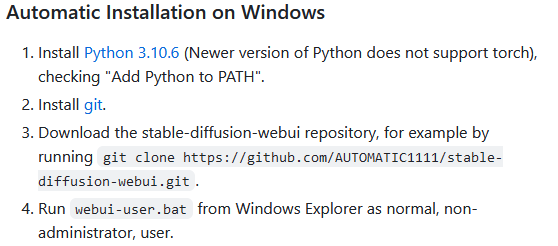
Se o link não te levou na seção correta, basta procurar na página até encontrá-la. Como o passo a passo sugere, a primeira coisa que precisamos fazer é instalar o Python 3.10.6. Existem versões mais recentes, mas para usar o A1111 e o SD, vamos precisar desta versão.
Para tal, clique no link fornecido no site, desça até a parte final da página e escolha a versão adequada para o seu caso, que muito provavelmente será Windows installer (64-bit).
Durante a instalação, você precisa marcar a opção “Add Python 3.10 to PATH”, em seguida escolher a opção “Install Now”, para começar a instalação, conforme mostrado na imagem que segue:

Se você é um programador, muito provavelmente conhece o git e nós vamos precisar instalar ele para poder utilizar o A1111. Para realizar este procedimento, abra o link fornecido no site no passo 2 e mais uma vez escolha a opção mais indicada para o seu sistema, que muito provavelmente será “Other Git for Windows downloads – 64-bit Git for Windows Setup”.
Dado que nós não vamos usar o Git para nada além de instalar o A1111, basta concluir o instalador seguindo as opções padrões, conforme mostrado abaixo.

Após concluído, vamos agora copiar o programa para o nosso computador. Note que idealmente devemos fazer isso em uma pasta não restrita do sistema. Apenas para fins do tutorial, eu vou usar a raiz do “C:\”.
Note que os modelos para fazer as imagens são grandes, algo como 2-4GB cada um, então escolha um dispositivo que tenha espaço disponível.
Dito isso, execute o Windows Explorer (Windows + E), abra o C:\, que está dentro do item “Este Computador”, segure o shift e aperte o botão direito em um espaço vazio, que deverá abrir um menu como o mostrado abaixo:

Escolha a opção “Abrir no Terminal”. Na nova janela que se abriu, copie o comando abaixo e pressione enter:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
O processo deverá ser concluído em pouco tempo, conforme mostrado abaixo:
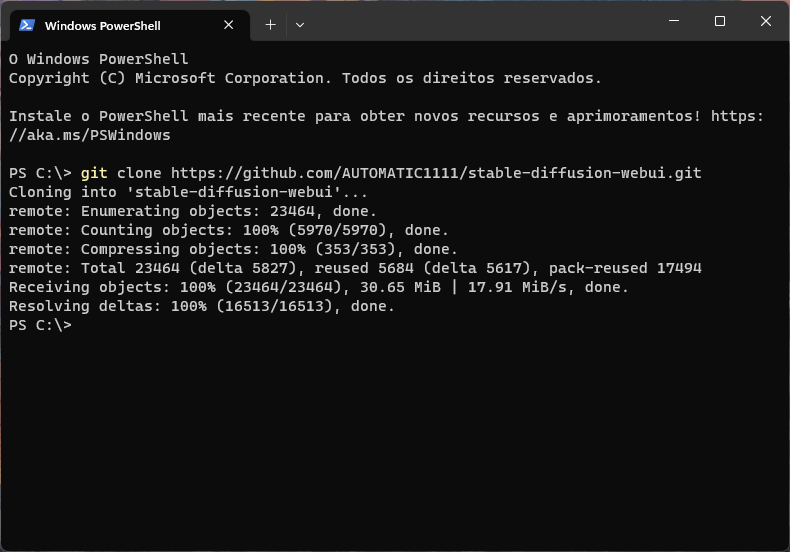
Você irá notar que apareceu uma pasta nova no seu “C:\”, chamada stable-diffusion-webui. Se você quer renomear a pasta para fins de organização, faça agora pois depois ficará bem mais complicado. Para fins do tutorial, eu vou seguir normalmente com o nome padrão.
Abrindo a pasta, vamos procurar um arquivo chamado “webui-user.bat”. Neste arquivo, pressione com o botão direito do mouse e escolha opção editar.
Dentro do arquivo, procure pela linha set COMMANDLINE_ARGS=, dê um espaço na frente e copie o código mostrado abaixo, como você pode ver na imagem que segue:
--opt-sdp-no-mem-attention --skip-torch-cuda-test --opt-channelslast --disable-nan-check --no-half-vae --xformers --autolaunch
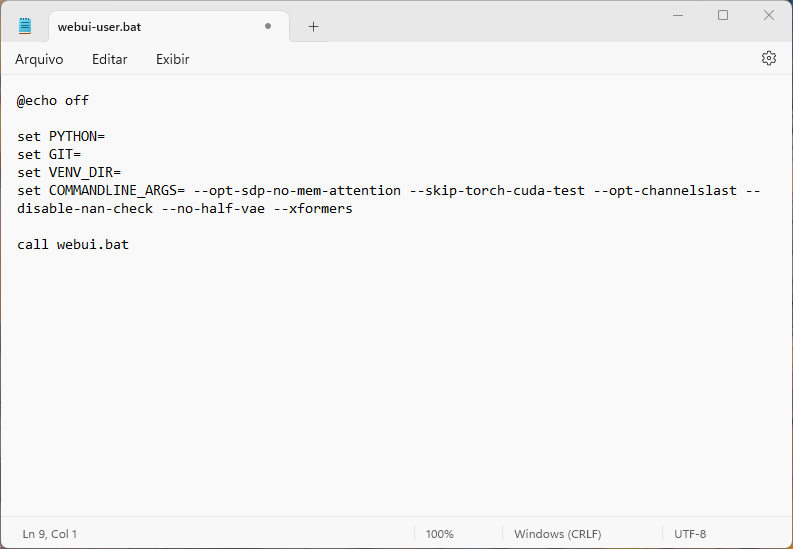
Atenção: você deve manter no código o “–xformers” apenas caso tenha uma placa de vídeo razoável, pois este comando reduz em quase metade o tempo em placas boas, mas prejudica muito em placas mais antigas. Feito isso, basta pressionar Ctrl + S para salvar e feche o arquivo em seguida.
Agora, vamos executar o “webui-user.bat”, para isso basta clicar duas vezes sobre ele e aguardar, como mostrado na imagem abaixo:
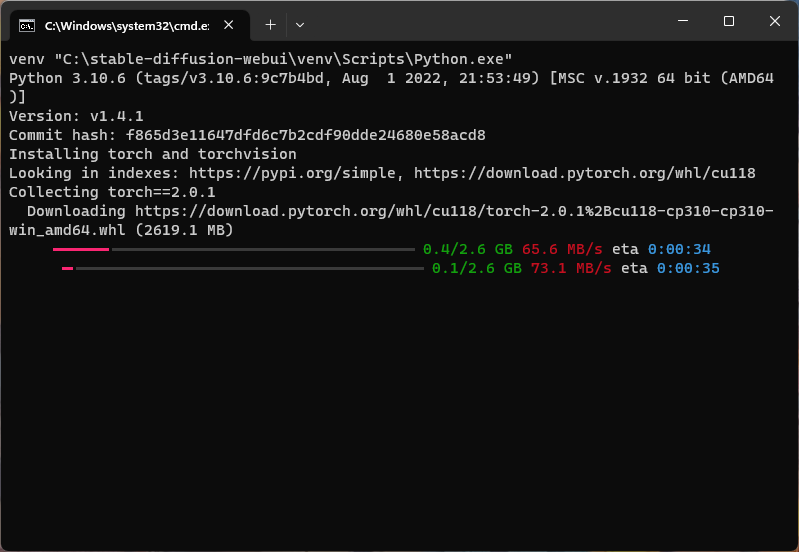
Na primeira vez que este programa for executado, será bem demorado e, a depender da qualidade da sua internet e do seu computador, pode demorar de alguns minutos até mesmo horas.
Depois de tudo instalado, ele deverá automaticamente abrir uma página na Internet, que nada mais é do que o A1111. Sempre que você quiser abrir o programa, basta executar este arquivo que abrimos a pouco.
Agora que o programa está instalado, vou explicar sobre o programa e nós vamos concluir o tutorial fazendo uma imagem juntos, tudo bem? Vamos lá, mãos à obra!
Interface do Programa
A interface pode parecer que irá lhe sobrecarregar, mas acredite, é bem simples depois que você pega o jeito da coisa. A sua interface deve ser parecida com esta mostrada abaixo:
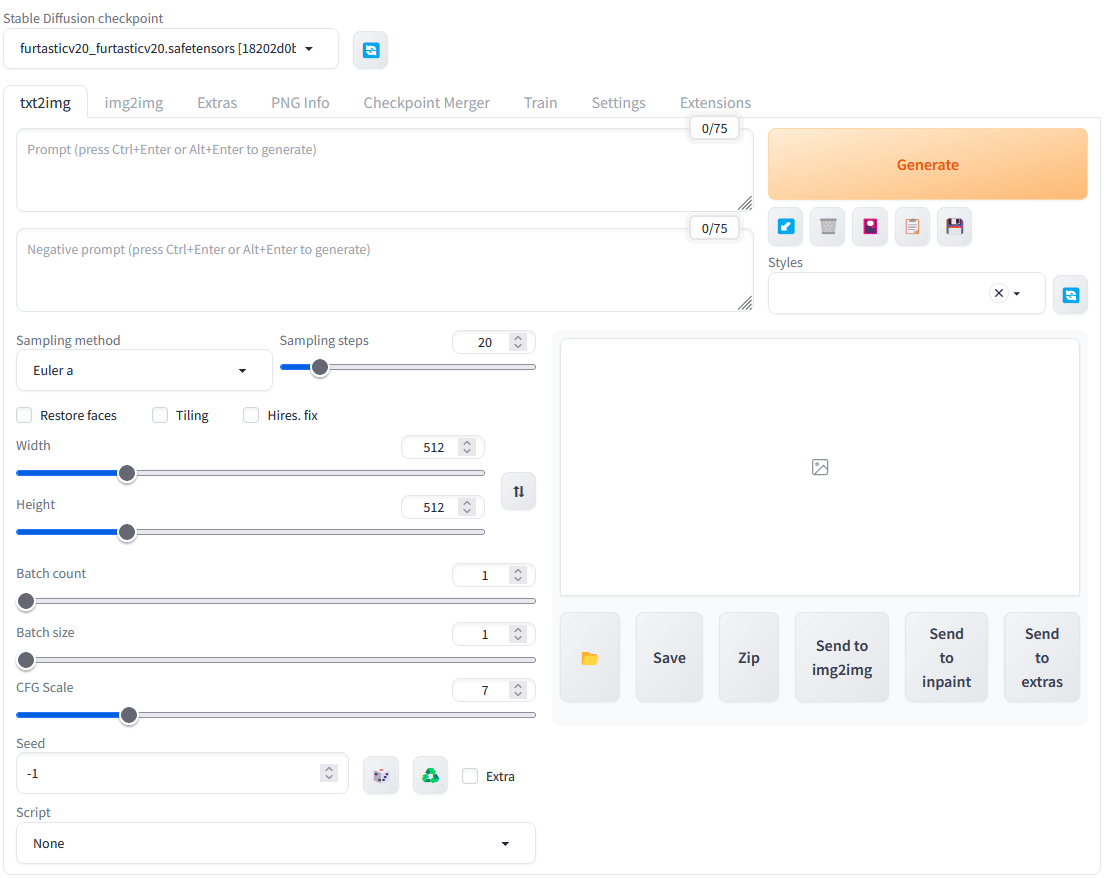
Nós vamos usar esta primeira aba, chamada txt2img (ou texto para imagem), que nada mais consiste em colocar textos, ou prompts, que iremos gerar imagens.
Prompt: Aqui você irá colocar “tags” em inglês que você deseja ver na imagem. Você pode usar palavras separadas por vírgulas, sentenças ou uma mistura dos dois.
Negative prompt: Aqui você irá colocar “tags” em inglês que você não deseja ver na imagem. Você pode usar palavras separadas por vírgulas, sentenças ou uma mistura dos dois.
Sampling method: Qual algoritmo será usado para gerar a imagem. Neste caso, ao falarmos de modelos, você verá que nos sites há algumas amostras que informam o algoritmo usado.
Width e Height: São a largura e a altura da foto, respectivamente. Estas medidas estão em pixels. No momento em que eu escrevo este tutorial, o ideal é utilizar dimensões de 512-1000 nestes campos, pois acima disso o programa começa a ficar maluco e dar resultados muito estranhos.
Resoluções recomendadas: Para imagens quadradas use 768×768, para retratos utilize 600×800 e para paisagem use 800×600. Mas atenção, verifique sempre na descrição do modelo usado quais são as resoluções recomendadas, pois a base de treino influencia bastante.
Hires. fix: Já que as resoluções nativas criadas pelo programa são consideradas baixas para os padrões atuais, uma das soluções é fazer o upscale, para isso basta selecionar esta opção e, em Upscale by, escolher quantas vezes a resolução irá “subir”. Eu recomendo 2, pois acima disso demora demais. O upscaler eu prefiro o Latent (nearest-exact). Já o Denoising strength é quanto o algoritmo vai “respeitar” a imagem no processo de upscale, normalmente eu prefiro deixar em 0,55. Atenção: Este processo é extremamente pesado para a sua GPU. Na minha experiência, um upscale de 2x, da forma que eu mencionei neste parágrafo, vai fazer o processo demorar de 7-8x mais para ser concluído.
Sampling steps: Quantas vezes a imagem será interativamente reprocessada e aprimorada. Quanto mais amostras, melhor o resultado tende a ser. Normalmente números entre 25-30 produzem imagens satisfatórias com o modelo que usei no começo do tutorial, mas para resultados bem positivos, utilize entre 100-150.
Batch count: Quantos lotes de imagem você deseja criar sequencialmente.
Batch size: Quantas imagens serão produzidas simultaneamente por lote. Por exemplo: eu posso querer fazer um lote de 4 imagens distintas, neste caso eu faria “1” count e “4” em size. Agora, se eu quiser dois lotes, com 3 imagens cada, eu colocaria “2” no count e “3” no size, gerando assim 6 imagens ao total. Note que criar imagens é extremamente pesado para o computador, principalmente a VRAM de sua GPU, por isso eu recomendo a começar com números baixos, como “1/1”.
CFG: O quanto os seus prompts precisam de fato serem cumpridos, quanto mais alto, mais restrito a imagem, quanto mais baixo, mais “criativa” a imagem ficará. Nos modelos que vou informar neste tutorial normalmente eu uso valores entre 6-12.
Seed: Para quem conhece jogos, isso aqui é o seu RNG, ou gerador de números aleatórios da sua imagem. Por padrão fica em -1, gerando de fato um seed aleatório em cada imagem sua, mas se você quiser replicar uma imagem, basta utilizar os mesmos prompts (positivos e negativos), com os mesmos modelos e o mesmo seed.
Ajustes antes de começar:
Os prompts são importantíssimos para as imagens que vamos gerar, pois podemos gerar uma coisa extremamente legal e posteriormente esquecer o que fizemos. Neste sentido, vamos mudar uma configuração para assegurar de deixar todas as tags salvas nos arquivos gerados, para isso vá até a aba “Settings”, no menu à esquerda escolha “Saving images/grids”, e certifique as opções “Add extended info (seed, prompt) to filename when saving grid” e “Save text information about generation parameters as chunks to png files” estão marcadas e clique em “Apply Settings”.
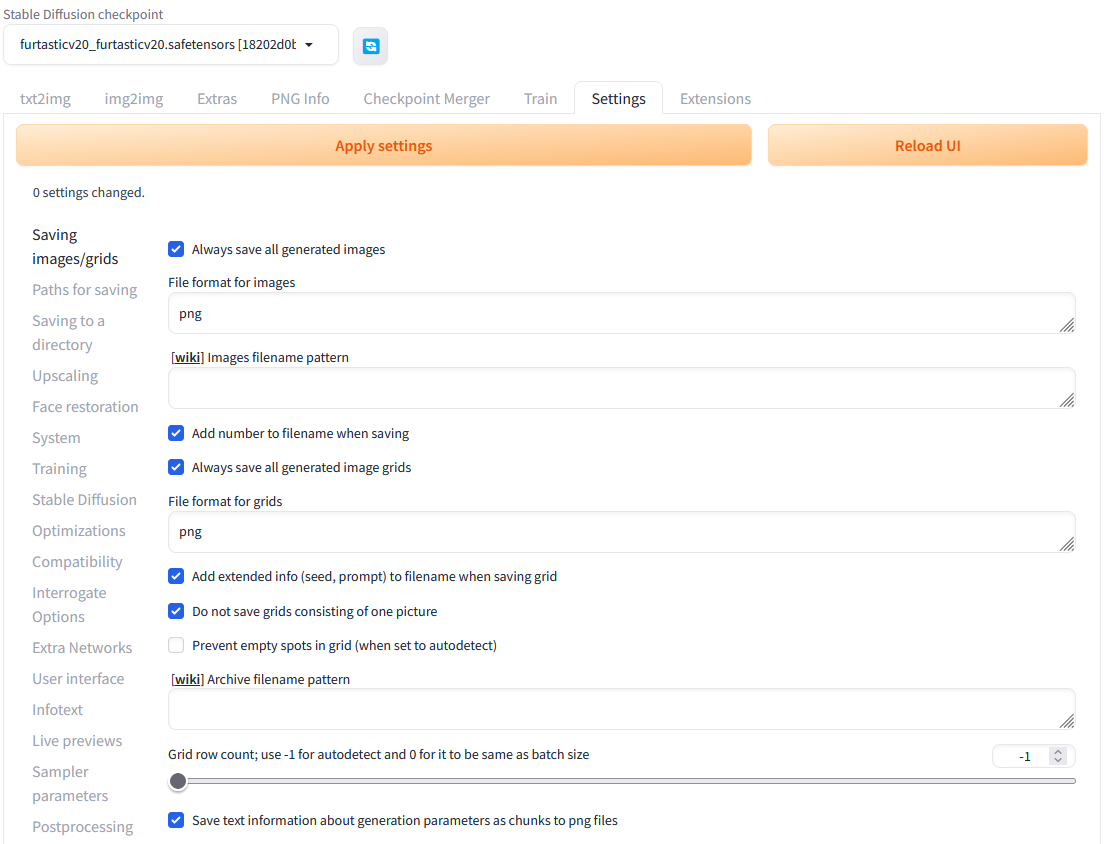
Outra coisa que acontece com frequência são imagens que saem completamente pretas por alguma razão. Para arrumar, ainda na Aba “Settings”, escolha o menu à esquerda escolha “Stable Diffusion”, marque a opção “Upcast cross attention layer to float32” e clique em “Apply Settings”. Aqueles comandos que ensinei no começo são justamente para mitigar este problema.
Como gerar Prompts:
Já que a imagem será gerada de um texto para imagem, ou txt2img, é muito importante que nós devemos aprender a nos comunicar melhor com o programa. Seguem algumas dicas:
Palavras ou sentenças dentro de parênteses são consideradas mais importantes, quanto mais parênteses, mais importantes.
Exemplo:
long snout, smile, sharp teeth – Importância Padrão
(long snout, smile, sharp teeth) – Importante
((long snout, smile, sharp teeth)) – Mais importante
Outra coisa importante: (long snout, smile, sharp teeth) também pode ser escrito como (long snout), (smile), (sharp teeth), não há mudanças em prioridade.
Palavras ou sentenças dentro de colchetes são consideradas menos importantes, quanto mais colchetes, menos importantes.
Exemplo:
long snout, smile, sharp teeth – Importância Padrão
[long snout, smile, sharp teeth] – Irrelevante
[[long snout, smile, sharp teeth]] – Mais irrelevante
Outra coisa importante: [long snout, smile, sharp teeth] também pode ser escrito como [long snout], [smile], [sharp teeth], não há mudanças em prioridade.
Além disso, temos também o controle de prioridade. Para tal, basta acrescentar dois pontos seguidos do multiplicador desejado.
Exemplo:
Vamos imaginar que eu realmente quero que “smile” apareça na imagem, neste caso, bastaria escrever smile:1.2, neste caso smile terá uma prioridade 20% maior de aparecer na foto. Eu recomendo usar multiplicadores de 1.1 até 1.5, mas é possível números menores que 1 (para tags mais irrelevantes) e maiores que 1 (para tags mais relevantes).
Modelos
Para poder gerar uma imagem, dado que este tutorial é focado para principiantes, nós vamos usar modelos gerados por outros usuários. Os dois maiores sites no momento para estes modelos são CIVIT AI e Hugging Face. Sabe a imagem do começo do tutorial? Foi feita usando o BB95 Furry Mix v9.0.
Para imagens de Furries, como esta que mostrei no começo do tutorial, eu posso recomendar, além do informado acima, o Furryrock v3.0, Furtastic V2.0, Indigo Furry Mix v4.5 Hybrid, entre outros.
Todos os arquivos de modelos que você pegar, devem ser salvos na pasta do A1111, em models\Stable-diffusion. No exemplo fornecido, seria na pasta C:\stable-diffusion-webui\models\Stable-diffusion.
Como informado anteriormente, eu não vou entrar em detalhes sobre Textual Inversions, mas saiba que estes recursos são usados como “negative prompts” para melhorar substancialmente o resultado final, pois são treinados pela AI para este fim. No caso destes modelos que mencionei acima, recomendo muito a fazer o download destes arquivos: badhandv4, easynegative e FurtasticV2.0 negative embeddings. Eles devem ser extraídos na pasta embeddings. No exemplo fornecido, seria na pasta C:\stable-diffusion-webui\embeddings.
Para saber se você puxou corretamente o modelo, basta clicar na seta branca com fundo azul que fica logo na primeira opção da interface, como mostra a imagem abaixo. Aparecendo o modelo, é que você fez certinho.
![]()
Agora, para saber se você puxou corretamente os Negative Embeddings que comentei a pouco, na primeira aba, txt2img, clique no quadro de “Negative prompt”, afinal eles são prompts negativos, clique no botão que parece um quadro roxo, é o terceiro abaixo do botão generate. Se você fizer corretamente, verá eles aparecendo na aba “Textual Invesion”, bastando clicar nestes para acrescer nos prompts.
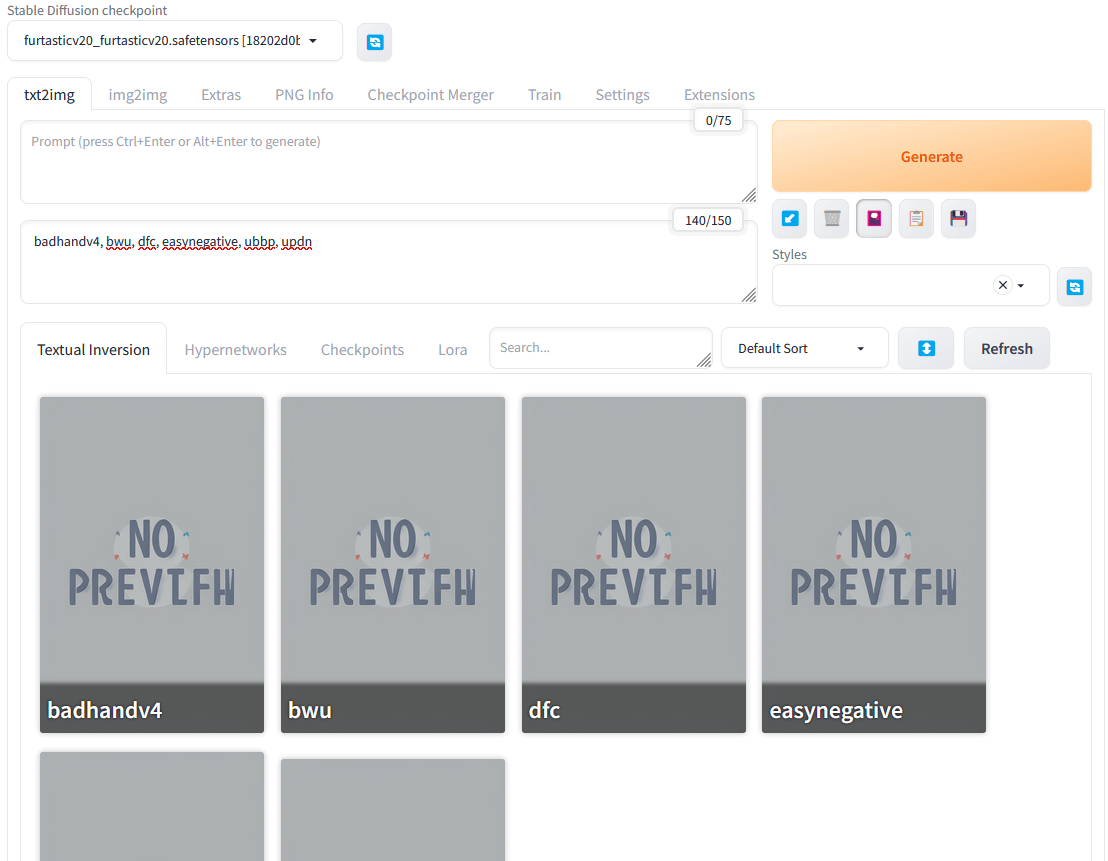
Lembre-se de separar os prompts por vírgulas depois de acrescê-los. Depois é só clicar no mesmo botão que a interface volta ao padrão.
Gerando sua primeira imagem
Depois de tanto treino, chegou a hora enfim de fazer a nossa primeira imagem. Neste caso, eu vou fazer junto com você, passo-a-passo, para que possamos chegar no mesmo resultado, tudo bem?
A imagem que é o nosso objetivo será esta abaixo:

Vamos começar?
Modelo: bb95FurryMix_v90.
Prompts: (duo:1.2), (anthro:1.1), (male muscular adult wolf with dark gray fur wearing a speedo, female adult fox with hazel fur, wearing a bikini), cute, couple, looking at viewer, cute eyes, hugging, on a island, big smile, white ear fluff, long snout, anatomically correct, intricate details, detailed background, backlighting, detailed fur, hyper realistic fur
Negative Prompts: ribcage, featureless, sketch, worst quality, low quality, feral, bad anatomy, bad hands, malformed hands, deformed limbs, blurry, cross-eyed, extra arms, speech bubble, extra legs, extra limbs, bad proportions, missing fingers, missing legs, poorly drawn hands, (signature, text, watermark), bad feet, ugly, bad legs, badhandv4, bwu, dfc, easynegative, ubbp, updn, multiple tails, no tail
Sampling steps: 100
Sampling method: Euler a
Hires. fix: Não
Width e Height: 768
Batch count e size: 1
CFG: 7
Seed: 850559093
Agora basta clicar no botão “Generate” e aguardar a conclusão do processo. Após a conclusão, ele irá criar uma pasta neste padrão “outputs\txt2img-images\AAAA-MM-DD” e dentro dela você deverá ver a sua imagem. Se tudo deu certo, ela deve ser idêntica a esta que coloquei acima.
PNG info:
Para concluir, o A1111 possui um recurso bem legal na aba PNG Info, basta arrastar uma imagem gerada para lá e ele irá mostrar todos os parâmetros usados na geração da imagem, isso claro se você seguiu as informações que coloquei no tópico “Ajustes antes de começar”.
Estando certinho, a sua imagem deve ficar como esta mostrada abaixo:

Esta é uma forma muito boa de se lembrar dos argumentos que você usou para fazer uma imagem que você gostou bastante. Se você quiser, por exemplo, gerar uma mesma imagem mas com outro modelo, é só clicar no botão “Send to txt2img”, escolher o modelo novo e clicar novamente no botão “Generate”.
E agora? Agora é curtir o programa, gerar imagens muito bacanas, pois a sua imaginação é o limite! Gostou do tutorial? Lembre-se que temos tutoriais interessantes que ajudam a melhorar o desempenho do seu computador e liberar os recursos físicos que são tão importantes para a geração de imagem, como você pode ver neste link: CTT Windows Utility.